Страница 1
Как работает AI ассистент
posted on 2026-05-31
В прошлом посте я писал о том, что хочу в качестве эксперимента сделать визуализацию работы своего кодового ассистента Codabrus.
И вот настали долгожданные выходные, и я объединил код фронта с бэком. Получилось как на демке.
Сообщения от пользователя отображаются синенькими блоками, ответы LLM - зелеными, а вызовы тулов - оранжевым. На блоки можно кликать чтобы видеть больше информации. Если блоки вызова тулов размещаются друг под другом - значит они выполняются параллельно. Использование акторной системы позволяет легко параллелить выполнение любой логики и у меня за выполнение каждого тула отвечает отдельный актор.
Тул у агента пока один - вызов bash команды. Для экспериментов этого достаточно, но для реальной работы надо будет добавить редактирование и прочее. А так же хочу в интерфейс добавить отдельное окно со стримингом размышлений агента - чтобы было видно чем он занят прямо сейчас.
Собираюсь использовать в Codabrus визуализацию работы AI ассистента
posted on 2026-05-28
Хочу сделать в своем AI-ассистенте Codabrus визуализацию того, как работает AI-ассистент. Традиционные кодовые ассистенты показывают интерфейс в виде чата. Я же хочу сделать некую диаграмму, которая каждое сообщение от ассистента и от пользователя будет показывать в виде отдельного блока. Вызовы тулов будут ответвлениями, а также, наверное, будет прикольно подобным же образом визуализировать запуски сабагентов.
Так можно будет проанализировать, насколько много работы сделал кодовый ассистент, что происходило в процессе - всё это будет более наглядно.
Пока что в виде заглушки сделал такой простенькую штуку - подключил JavaScript библиотеку X6 от Alibaba для отрисовки диаграмм. Плюс подключил туда CLACK-SSE для того, чтобы можно было новые элементы добавлять, пуша их с сервера. Таким образом, когда что-то происходит во время работы кодового ассистента, я смогу обновлять диаграмму в веб-интерфейсе.
Вот такая пока идея. Наверное, в выходные доберусь до того, чтобы связать этот интерфейс с реальным ассистентом.
Итерация которую можно прервать
posted on 2026-05-16
Итерация которую можно прервать. С акторами не всё так просто.
Вот вам небольшая демка того, как в системе акторов можно реализовать итерацию таким образом, чтобы её можно было безопасно прервать. Я собираюсь использовать этот подход для того, чтобы организовать работу с код-ассистентом и тулами, которые он запускает. Это нужно сделать так, чтобы код-ассистента можно было прервать в любой момент и сделать это безопасно.
В этом демо используется фреймворк Sento, реализующий актеры для Common Lisp.
Вот полный код примера:
(defun make-interruptable-actor-loop-example ()
(ac:actor-of *sys*
:destroy (lambda (&rest args)
;; По сообщению :stop актор будет полностью
;; остановлен и его нельзя будет запустить ещё раз
(log:info "Destroy called with ARGS = ~A" args))
:receive (let ((stopped nil))
(lambda (message)
(log:info "Processing" message)
(case message
;; Но с помощью :break итерацию можно приостановить,
;; а потом продолжить заново с помощью :run.
(:break
(log:info "Stopping")
(setf stopped t))
(:run
(log:info "Running")
(setf stopped nil)
(act:tell act:*self* :next-iteration))
(t
(unless stopped
(log:info "Sleeping")
(sleep 3)
(log:info "Going to next iteration")
(act:tell act:*self* :next-iteration))))))))
Итерация которую можно прервать
posted on 2026-05-16
Итерация которую можно прервать. С акторами не всё так просто.
Вот вам небольшая демка того, как в системе акторов можно реализовать итерацию таким образом, чтобы её можно было безопасно прервать. Я собираюсь использовать этот подход для того, чтобы организовать работу с код-ассистентом и тулами, которые он запускает. Это нужно сделать так, чтобы код-ассистента можно было прервать в любой момент и сделать это безопасно.
В этом демо используется фреймворк Sento, реализующий актеры для Common Lisp.
Вот полный код примера:
(defun make-interruptable-actor-loop-example ()
(ac:actor-of *sys*
:destroy (lambda (&rest args)
;; По сообщению :stop актор будет полностью
;; остановлен и его нельзя будет запустить ещё раз
(log:info "Destroy called with ARGS = ~A" args))
:receive (let ((stopped nil))
(lambda (message)
(log:info "Processing" message)
(case message
;; Но с помощью :break итерацию можно приостановить,
;; а потом продолжить заново с помощью :run.
(:break
(log:info "Stopping")
(setf stopped t))
(:run
(log:info "Running")
(setf stopped nil)
(act:tell act:*self* :next-iteration))
(t
(unless stopped
(log:info "Sleeping")
(sleep 3)
(log:info "Going to next iteration")
(act:tell act:*self* :next-iteration))))))))
Зачем мне CLOS объекты как состояние акторов в Sento?
posted on 2026-05-11
На этой небольшой демке хочу показать, как я собираюсь использовать CLOS-объекты как состояние акторов в моем кодовом ассистенте Кодабрус. Для реализации акторов я использую библиотеку Sento, а CLOS-объекты в качестве состояния мне нужны для того, чтобы это состояние можно было сериализовать на диск и потом продолжить работу системы с того же места, на котором остановился пользователь.
Демка нового поиска на Ultralisp
posted on 2026-05-05
Демка нового поиска на Ultralisp.org
Не так давно я обновил Ultralisp и сделал там поддержку фреймворка reblocks-ui2, а теперь настало время очередных изменений. Вчера я выкатил обновленный поиск. Если раньше поиск по Ultralisp находил только символы и искал он по докстрингам этих символов, то теперь поиск работает также по ASDF системам и по проектам.
То есть поиск идет по трем сущностям:
- проектам;
- ASDF системам;
- символам.
При этом проект включает в себя ASDF системы, а каждая ASDF система включает в себя набор символов. Пакеты я индексировать не стал, потому что для них почему-то редко пишут докстринги.
Примечательно, что всё это реализовано нейронкой GLM 5.1 под моим чутким руководством! Надеюсь в будущем добраться и до других улучшений, которые давно планировал - нейронки реально разгружают от рутины написания большей части кода, оставляя мясным хозяевам самое интересное - дебаг неправильно проставленных скобочек! :))))
Циклическая зависимость в mgl-pax
posted on 2026-04-19
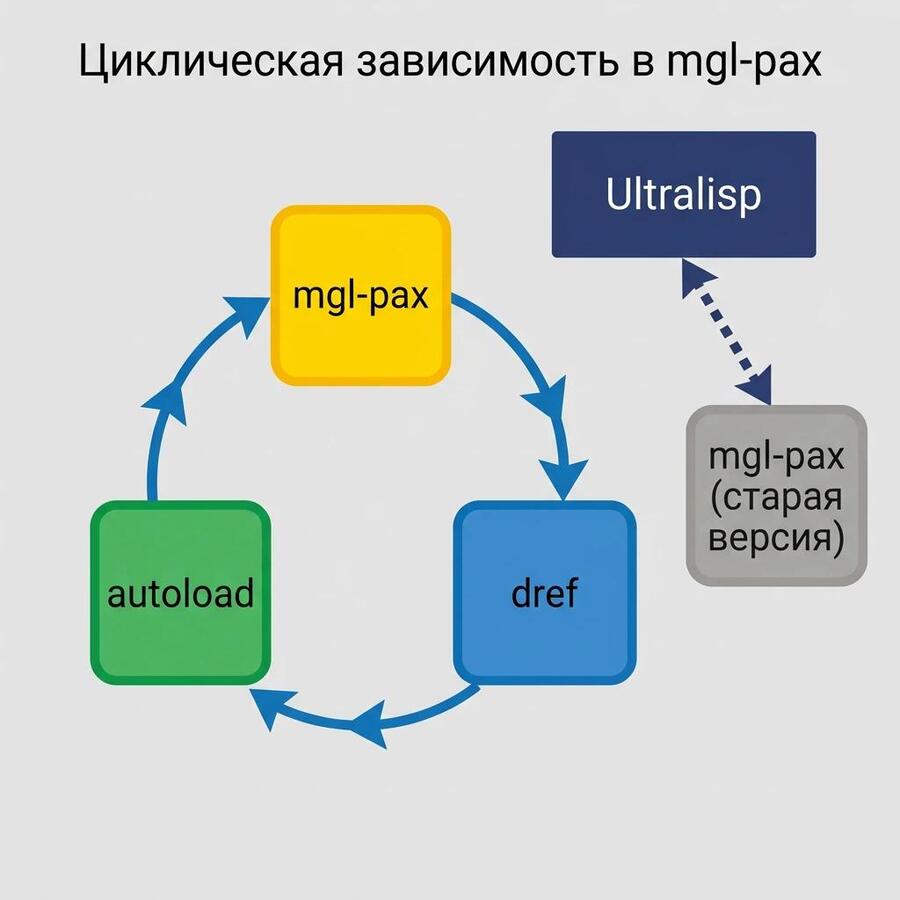
В эти выходные решал проблемку с отвалившейся named-readtables на UltraLisp.
Named-readtables библиотека довольно много где используется, и то что она стала недоступна - большая проблема.
Дебажить пришлось долго, и вот что оказалось.
Звёзды так сошлись, что:
• Ultralisp выкидывает из диста проект при ошибках проверки очередного коммита (это стоит починить • Gábor Melis намутил в своих либах циклическую зависимость, когда mgl-pax зависит от свежей версии dref и наоборот и попытался это решить с помощью либы autoload. • Процесс, проверяющий проекты в Ultralisp сам по себе зависел от старой версии mgl-pax, которая была притянута как транзитивная зависимость • Новый mgl-pax конфиликтовал со старым и не мог просто подгрузиться в образ где уже была старая версия. • Из-за этого не мог провериться dref которому нужна новая версия mgl-pax. • То есть, эти три либы mgl-pax, dref и autoload надо было обновлять все разом, а Ultralisp так не умеет.
В итоге, чтобы обновить эту пачку либ пришлось пересобрать сам Ultralisp так, чтобы там была вкомпилирована свежая версия mgl-pax. Теперь всё заработало.
Вывод - надо уменьшать количество зависимостей в бинаре, который чекает загрузку других библиотек. В идеале - до нуля!
Жизненные уроки
posted on 2026-04-18
Последнее время я вернулся к работе над своим проектом кодового ассистента. Идея в том, чтобы сделать такого ассистента, которого можно расширять и интерактивно отлаживать в процессе его работы. Конечно, я его делаю на CommonLisp, но многие вещи делаю с помощью другого кодового ассистента - OpenCode. Мой проект, кстати, называется Codabrus. Если интересно, подписывайтесь на обновление этого проекта на GitHub, ставьте ему звездочки, шерьте с друзьями.
Так вот, для разработки я сейчас использую OpenCode, и у него есть один инструмент, позволяющий сделать eval внутри работающего Lisp процесса. А в качестве модели я использую подписку на GLM 5.1. В целом, GLM неплохо справляется с разработкой на CommonLisp, лишь чуть хуже, чем Claude Sonnet, я бы сказал.
Единственное, с чем у него частенько возникают проблемы, это со скобками. Тут он часто косячит и потом не может правильно выставить скобки. Ну, есть и другие проблемки, которые там, тут, здесь всплывают. Но, что удивительно, есть один трюк, который почти все эти проблемы может полечить, если его планомерно использовать.
Этот трюк я подсмотрел на стриме у одного из коммон-лиспера - Николая Матюшева. Заключается трюк в том, что модель нужно научить учиться. Да, многие модели у себя в памяти как бы и так хранят какие-то знания о вашем проекте, окружении и прочем, но я предпочитаю сохранять знания явно.
Как это делается? Вы просто в промпте внутри файлика AGENT.md просите модель выписывать те важные уроки, которые она получила в ходе работы над каждой сессией. И модель выписывает эти уроки в файлик lessons-learned.md. Так, например, когда у меня случилась проблема с тем, что модель никак не могла расставить скобочки в коде, я попросил ее разобраться, в чем была проблема и придумать решение на будущее так, чтобы этой проблемы больше не возникало.
Модель проанализировала всю историю текущей сессии и выписала несколько важных пунктов. Таких, например, как она поняла, что если функция слишком большая и имеет большой уровень вложности, то модели сложнее правильно расставить скобки. И значит функцию надо делать короче и поменьше. Кроме того, она взяла и написала для себя кусочек кода, который позволяет ей валидировать открывающиеся и закрывающие скобки. Все это моделька сохранила в файлик lessons-learned.md. И после этого я не замечал, чтобы она зацикливалась, пытаясь правильно поставить скобки в коде.
Так что, приём очень полезный. Единственное, чего я опасаюсь, это того, что этот файлик lessons-learned будет разрастаться. Кроме того, не очень понятно, что делать с шерингом этих знаний, потому что многие лайфхаки, которые модель для себя выписывает, были бы полезны и в других проектах со схожим стэком. А значит, шерить знания как-то надо. Таскать из проектов проект файлики lessons-learned.md не очень хорошо, потому что тогда будет сложно эти знания обновлять.
И вот я думаю, что в своем кодовом ассистенте Codabrus я, наверное, придумаю какую-то структурную память, которая позволит шерить такие знания между проектами, над которыми работает кодовый ассистент. А может быть, даже и шерить их куда-то наружу в виде лайфхаков для других AI-ассистентов.
Некоторое время назад один из коллег опубликовал свою поделку, которая...
posted on 2026-04-02
Некоторое время назад один из коллег опубликовал свою поделку, которая показывает, сколько осталось квоты на использование нейросетей. Она была написана на Python с отдельной библиотекой для встраивания в тулбар на OS X. Я подумал, что это хороший проектик, чтобы попробовать переписать его на Common Lisp с помощью нейросетей.
► Как нейросеть писала код
У меня были исходники коллеги на Python. Я дал LLM простой запрос — переписать программу на Common Lisp, используя существующие библиотеки, найденные через ql:system-apropos. В качестве ассистента использовал Claude Code + модель Opus 4.6.
Нейронка написала код. В процессе она даже нашла библиотеку для работы с Objective-C, потому что для отображения пунктов меню и иконки в macOS нужно использовать фреймворк на Objective-C. Нейронка оценила библиотеку, решила, что она недостаточно хороша, отказалась от неё и написала свою обёртку над Objective-C через CFFI.
► Отладка и запуск
Конечно, с первого раза программа не заработала. Я сделал несколько итераций. К сожалению, такие графические программы неудобно запускать через мой MCP-сервер для разработки на Common Lisp, потому что при неправильном создании биндингов программа крэшится и роняет вместе с собой весь MCP-сервер. Пришлось запускать программу вручную и скармливать тексты ошибок ассистенту.
После нескольких итераций ассистент допилил программу до состояния, когда она начала запускаться и работать достаточно стабильно. Теперь у меня есть полный аналог той программы, которую написал коллега, но на Common Lisp. Её очень удобно расширять, добавляя новый функционал прямо через REPL.
► Что дальше
Но интереснее другое. Раньше у меня была похожая программка для встраивания в тулбар macOS под названием Barista. Она была написана на LispWorks с его фреймворком CAPI. Там было ограничение: при распространении программы через компиляцию в LispWorks отключаются возможности компилятора, то есть нельзя подгружать динамические плагины.
Теперь я могу переписать Barista так, чтобы использовался SBCL, и там не будет таких ограничений. Программа станет полностью расширяемой с помощью Lisp-скриптов.
Портируем microGPT на Common Lisp с помощью LLM
posted on 2026-03-14
Смотрите чего я навайбкодил: https://github.com/40ants/microgpt
Это порт на Common Lisp скрипта microgpt, который недавно опубликовал Andrej Karpathy.
Эта штука включает в себя код трансформера и инференс. То есть она может обучиться на каких-то входных текстах, а потом генерировать похожие тексты. Всё как у больших LLM, только буквально в одном Python-скрипте. Ну и, конечно, эта штука больше создана для обучения, а не для того, чтобы показывать хорошую производительность.
В этом примере она учится на корпусе русских имен и может генерить новые, похожие по написанию:
% ./microgpt.py
num docs: 484
vocab size: 57
num params: 5152
step 1000 / 1000 | loss 2.3474
--- inference (new, hallucinated names) ---
sample 1: Небромир
sample 2: Миловета
sample 3: Милана
sample 4: Свеладр
sample 5: Милана
sample 6: Ратевоба
sample 7: Миловисла
sample 8: Крана
sample 9: Бородосл
./microgpt.py 54.06s user 0.82s system 99% cpu 55.011 total
Я подумал, что это хороший пример, чтобы попробовать, как LLM справится с переписыванием этого кода на Common Lisp.
Промпт для переписывания был очень простой. Буквально я сказал LLM: "Вот тебе код на Python, сделай мне то же самое, но на Common Lisp, для загрузки датасета используй либу Dexador". При этом я использовал в качестве агента Claude Code и нейросеть Claude Sonnet 4.6.
Что меня удивило - то что нейросеть сама создала ASDF систему, а так же решила декомпозировать код на модули, а не склеила всё в один большой скрипт.
Первоначальная версия которая получилась, работала аналогично питоновской, но в 5 раз быстрее:
% time roswell/microgpt.ros
num docs: 484
vocab size: 57
num params: 5152
step 1000 / 1000 | loss 1.9185
--- inference (new, hallucinated names) ---
sample 1: Велослав
sample 2: Бореслав
sample 3: Любра
sample 4: Влавослав
sample 5: Добран
sample 6: Любегост
sample 7: Светисл
sample 8: Вирослав
sample 9: Зослав
roswell/microgpt.ros 9.41s user 0.61s system 99% cpu 10.038 total
Дальше я просил LLM проанализировать что можно сделать чтобы повысить производительность и в итоге было сделано следующее:
*CLOS классы педеланы на структуры: * ```
roswell/microgpt.ros 6.00s user 0.47s system 99% cpu 6.489 total
То есть, после этого программа стала **быстрее python** оригинала **почти в 10 раз**.
А вот после объявления ftype и inline для некоторых функций, производительность улучшилась незначительно:
roswell/microgpt.ros 5.70s user 0.51s system 99% cpu 6.232 total
```
У меня не было цели упарываться в оптимизацию, но думаю можно выжать ещё больше скорости если захотеть. Основной темой эксперимеынта было - проверить, как LLM справится с подобным проектом. Ведь иногда так бывает, что для Common Lisp какой-то библиотеки нет, но она есть для другого языка. Переписывать вручную - занятие грустное, но если можно сделать это автоматически с помощью LLM и сэкономить себе много часов работы, то почему нет?
Created with passion by 40Ants ![]()
